React Native Enterprise Network Architecture Part 2: Token Guard, Circuit Breaker & Resilience Layer (2026 Guide)
React Native Enterprise Network Architecture Part 2 introduces production-grade resilience patterns including token refresh guards, circuit breaker implementation, client-side rate limiting, request orchestration, and observability. Learn how to prevent 401 storms, backend overload, and cascading failures in real-world mobile systems.
ALLTYPESCRIPTJAVASCRIPTREACT NATIVEREACTMOBILE DEVELOPMENT
Token Guards, Circuit Breakers, Rate Limiting & Observability
Part 1 built the foundation.
Part 2 builds the system that survives production.
Because real-world mobile systems face:
Expired tokens mid-session
Parallel API bursts
Retry amplification
Backend instability
Weak networks
Offline users
Hidden production errors
Resilience is not accidental.
It is engineered.
What We Are Building in Part 2
Token Refresh Guard (Prevent 401 Storms)
Request Orchestrator
Client-Side Rate Limiter
Circuit Breaker Pattern
Observability Layer
All implemented inside your existing layered architecture.
1️⃣ Token Refresh Guard — Preventing 401 Storms
🔥 The Production Failure Scenario
User opens dashboard.
10 API calls fire simultaneously.
Access token expired.
All 10 return 401.
Without protection:
All 10 trigger refresh.
Backend receives 10 refresh calls.
That is a refresh storm.
Diagram: 401 Storm Without Guard
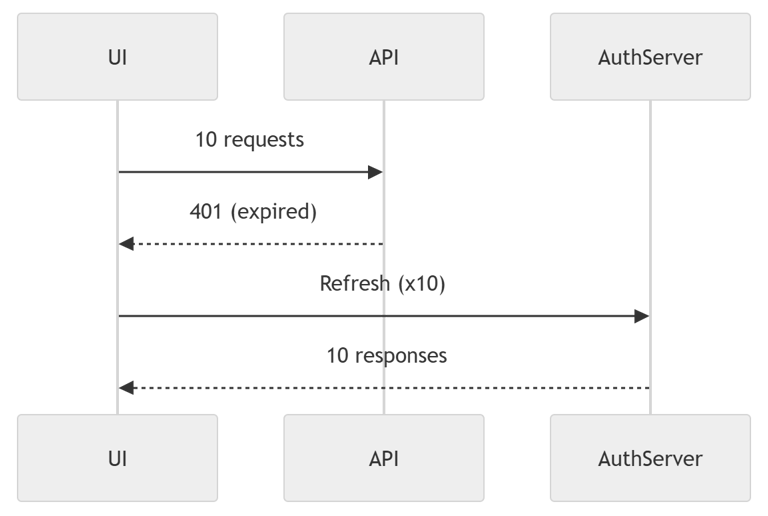
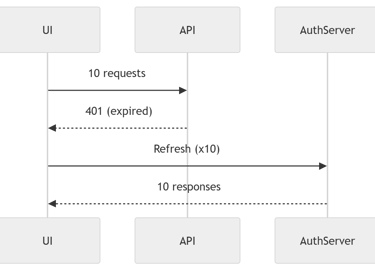
Explanation
Every request independently detects 401
Every request triggers refresh
Backend receives duplicated refresh calls
Traffic spikes
Race conditions occur
This is extremely common in poorly designed apps.
Diagram: Token Refresh Guard (Correct Architecture)
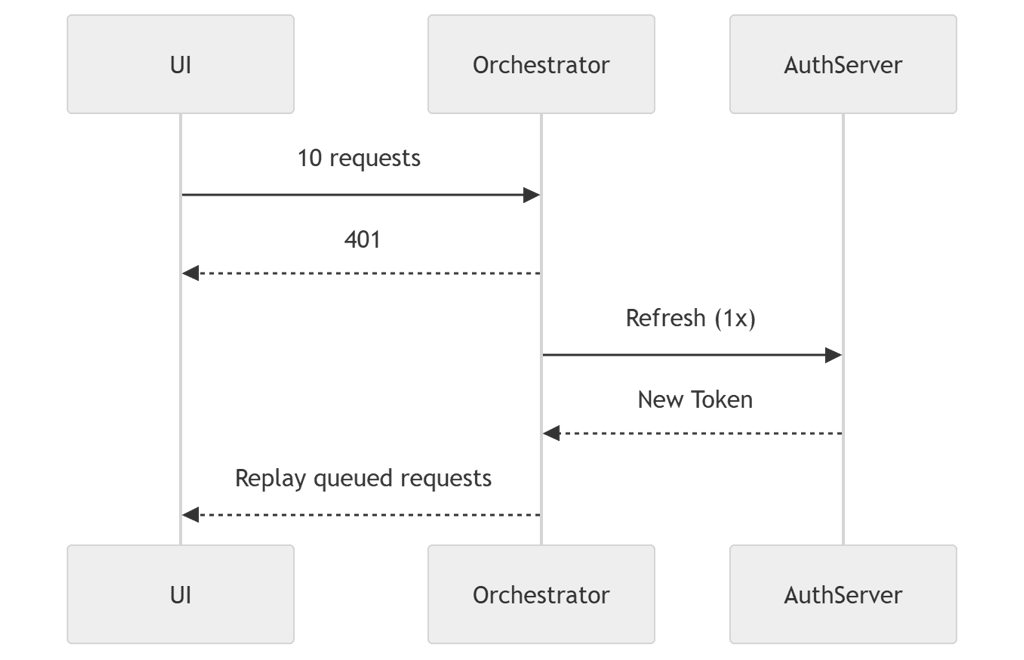
Explanation
First request triggers refresh
All other 401s wait for same Promise
Only one refresh call executed
All failed requests replay safely
That is enterprise-safe token handling.
Implementation
2️⃣ Request Orchestrator — The Traffic Controller
Resilience must not leak into UI or services.
It belongs in one place.
The orchestrator coordinates:
Rate limiting
Circuit breaker
Token guard
Error normalization
Retry strategy
Diagram: Orchestrator Execution Pipeline
Explanation
Each stage has one responsibility:
Rate Limiter → controls burst traffic
Circuit Breaker → prevents cascading failures
Token Guard → ensures valid auth
Transport → executes request
Normalizer → standardizes errors
This centralization prevents architectural entropy.
Implementation
3️⃣ Client-Side Rate Limiting — Traffic Discipline
Mobile apps can generate backend floods:
Scroll pagination
Retry bursts
Rapid mount/unmount cycles
Without rate control:
You become your backend’s DDoS attacker.
Diagram: Traffic Without vs With Rate Limiting
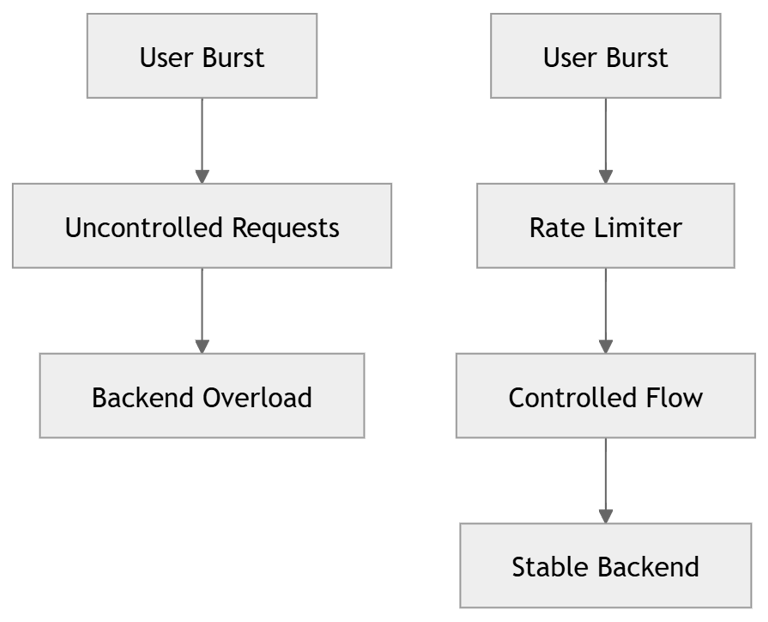
Explanation
Without limiter:
All requests fire instantly
Backend spike
With limiter:
Requests spaced evenly
Backend load stabilized
Implementation
4️⃣ Circuit Breaker — Stopping Cascading Failure
When backend fails:
Retries increase traffic.
Traffic increases failure.
Failure increases retries.
This is cascade collapse.
Diagram: Circuit Breaker State Machine
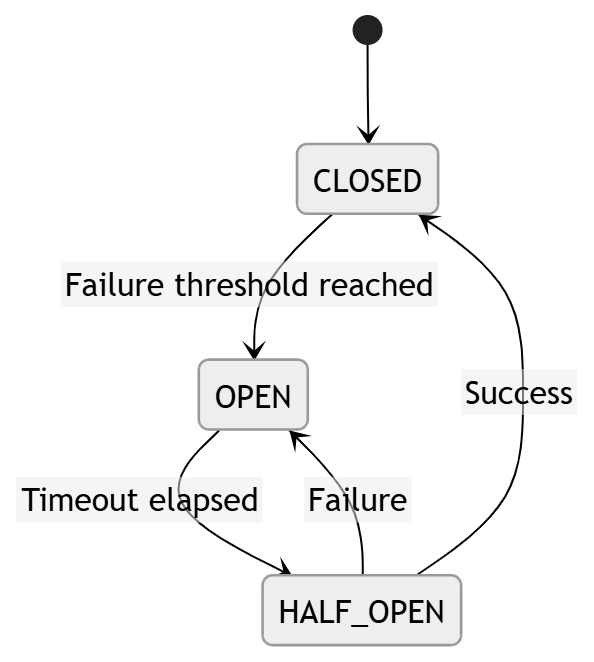
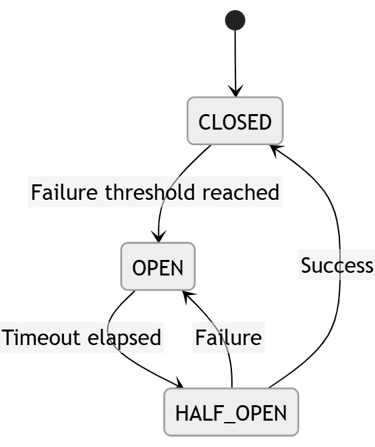
Explanation
CLOSED → normal state
OPEN → block requests temporarily
HALF_OPEN → test backend health
If success → restore system
If failure → reopen
This prevents retry amplification loops.
Implementation
5️⃣ Observability — Engineering Visibility
If you can’t measure it, you can’t improve it.
Production systems require:
Structured logging
Correlation IDs
Request duration tracking
Endpoint metadata
Diagram: Observability Flow
Explanation
Each request becomes traceable:
Unique ID
Start timestamp
Duration
Endpoint
Status
This enables integration with:
Sentry
Datadog
Elastic
CloudWatch
Implementation
Combined Execution Flow (Final System)
Each layer owns exactly one responsibility.
This is controlled complexity.
⚠ Tradeoffs
Yes, this introduces:
More abstraction
More files
Slight overhead
But you gain:
Failure isolation
Backend protection
Secure token lifecycle
Predictable retries
Production traceability
That is an intentional engineering tradeoff.
Final State After Part 2
You now have:
Clean architecture (Part 1)
Production resilience layer (Part 2)
Token refresh protection
Backend meltdown prevention
Structured observability
Offline durability
Your app is no longer feature-driven.
It is system-driven.
📌 What Comes in Part 3
Durable Offline Mutation Queue
Idempotent Replay Strategy
Sequential Controlled Replay Engine
Background Sync Worker
Performance Measurement Layer
Chaos Engineering Validation
Full End-to-End System Lifecycle
Final Thought
Most mobile apps make API calls.
Few engineer distributed systems inside a mobile client.
When you implement:
Token locking
Circuit breakers
Rate limiting
Structured observability
You move from coding features to engineering systems.
And that is what defines senior-level architecture.
GitHub Repository
The complete implementation of this architecture is available on GitHub.
It contains the full React Native networking control plane, including:
request orchestration
resilience systems
circuit breakers
token refresh guard
offline mutation queues
observability infrastructure
performance governance
The repository demonstrates how to build a production-grade networking layer for mobile systems, designed to handle real-world constraints like unstable connectivity, authentication expiration, and backend instability.
GitHub Repository
https://github.com/adarsh-bharadwaj/react-native-network-control-panel
You can explore the full implementation, architecture diagrams, and system components used throughout this series.
React Native Enterprise Network Architecture Series
This article is part of the React Native Enterprise Network Architecture series, which explains how to design a production-grade networking system for mobile applications.
The series walks through the full architecture step by step — from foundational layering to resilience engineering, durability systems, real-time consistency, and production observability.
Part 1 — Clean Foundation & Production Setup
Establishes the layered architecture foundation separating UI, domain hooks, services, and networking systems.
Part 3 — Durability & Systems Engineering
Focuses on offline durability, mutation queues, replay engines, and safe recovery mechanisms for unreliable mobile networks.
Part 4 — Real-Time Systems & Distributed State Convergence
Explores event-driven architecture for real-time updates, event buses, and distributed state convergence inside mobile applications.
Part 5 — Observability, Performance Governance & Reliability
Covers production observability systems, including distributed tracing, structured logging, metrics collection, and performance budgets.
Together, these articles demonstrate how to move from feature-driven mobile apps to system-engineered mobile platforms.